LEX + YACC 计算器语法分析器
前言
实现一个计算器语法分析器的方法有两种:
- 第一种是使用单调栈建立后缀表达式,这样的方法不用借助任何工具,基于笛卡尔树的理论基础。
- 第二种方式是使用 LEX 和 YACC 等词法文法分析工具,它们的支持更加灵活,基于文法分析的理论基础。
本文将要介绍的是第二种方法,它不仅可以用于构建计算器,其实更能构建编程语言,所以这是大学中的一门课程叫作 编译原理 。而关于第一种方法,我之前写过一篇文章 对于后缀表达式的思考 - 栈。
好吧,这其实就是我们编译原理课的一个实验,写着感觉挺有意思的,于是写了这篇文章。
相关工具
建议使用 Linux 系统进行实验会方便很多,我使用的 Ubuntu22.04。
-
g++:一种 C++ 编译器。编译原理课程老师可能会教你使用 C 编写,但我想说你其实可以使用 C++ 编写。
本文还会建议你将词法分析、文法分析、语法分析三者分离,然后使用
g++编译链接。 -
flex:一种词法分析器。Lexical analyzer generator. A rewrite of lex with extensions to the POSIX specification.Given the specification for a lexical analyzer, generates C code implementing it.NOTE: long options don’t work on OpenBSD.More information: https://manned.org/flex.
-
bison:一种文法分析器。GNU parser generator. Bison is a general-purpose parser generator that converts an annotated context-free grammar into a deterministic LR or generalized LR (GLR) parser employing LALR(1) parser tables. As an experimental feature, Bison can also generate IELR(1) or canonical LR(1) parser tables. Once you are proficient with Bison, you can use it to develop a wide range of language parsers, from those used in simple desk calculators to complex programming languages. More information: https://www.gnu.org/software/bison/.
-
graphviz:一种代码绘图工具,用于绘制表达式的抽象语法树。Render an image of a linear directed network graph from a graphviz file.Layouts: dot, neato, twopi, circo, fdp, sfdp, osage & patchwork.More information: https://graphviz.org/doc/info/command.html.
我另外推荐一种代码绘图工具: mermaid。画出的图更好看,文档更加简明易读。但需要使用
npm安装,因此没有在这里使用。
安装相关工具:
1 | which g++ || sudo apt install build-essential |
总体结构
学过编译原理的都知道,语法分析分为三个部分:词法分析、文法分析、语法分析。其中词法分析由 flex 完成,文法分析由 bison 完成。而语法分析和数据结构较为复杂,则由额外的文件 calculator.cpp 完成。
不要将词法分析和文法分析与语法分析和数据结构放在同一文件中 ,因为通常词法分析和文法分析只需定义正则表达式和执行简单的语句。而数据结构的定义则相对复杂,这可能需要数百行代码。我们知道文法分析会产生 book.y 文件,它具有自己独特的语法,当然你也可以在里面写 C++ 语法,但是你的 IDE 对其的自动补全和代码高亮支持通常不好。因此在 book.y 中进行简单的函数调用,而在 calculator.cpp 中书写主要语法分析和数据结构可以很好的解决这个问题,同时大大提高你的编程效率。
来看我们的项目组织结构,主要由 book.l、book.y、calculator.cpp 三个文件组成:
flowchart BT
subgraph g++
s1(lex.yy.cpp) & s2(book.tab.cpp) & s3(calculator.cpp) --> 0(main)
h2(book.tab.hpp) & h3(calculator.hpp) --> s1
h3 --> s2 & s3
end
subgraph "lex / yaac"
g1(book.l) -.-> s1
g2(book.y) -.-> h2 & s2
end
subgraph run.sh
t1(test.in) -.->|"./run.sh < test.in"| 0 -.->|"./main > book.gv"| t2(book.gv)
t2 -.->|graphviz| p1("book.gv.png\nbook.gv.svg")
end
尝试运行项目:
1 | ./env.sh # 检查并安装环境支持 |
flex 与 bison 的链接
flex 在项目中扮演词法分析的角色(即 book.l 文件),使用正则表达式识别对应的 token 并返回对应的 token 编号。而这里的 token 编号包含在 bison 额外生成在 book.tab.hpp 文件中,这是 bison 专门用于链接 flex 而生成的文件,因此你还需要在 book.l 文件中 #include "book.tab.hpp"。另外,flex 还需要 #include "calculator.hpp",这实际不是 book.l 需要而是 book.tab.hpp 需要,因为 bison 不会将头部宏定义复制到 book.tab.hpp 中。
同时 flex 中进行的 yylval.str = yytext; 会向 bison 传递,bison 中只需定义这些 token 类型为 str 即可使用形如 $1 获取 flex 捕获的文本。
另外,事实上 flex 和 bison 在 C++ 支持方面都仅仅是宏支持。它不会检查用户书写的 C++ 或 C 代码是否正确,只是将它连同分析器生成的代码一同复制到外部文件中,因此你可能只会在使用 g++ 进行编译链接时才会发现奇怪的编译错误。
bison 与 calculator 的链接
bison 在项目中扮演文法分析的角色(即 book.y 文件),它使用 LALR(1) 文法分析并调用相应 C++ 代码。bison 负责了项目的主要调用逻辑,你可以看到 bison 中大量的 $$ = new NodeExp(..., $1, ...),实际就是在组织抽象语法树的结构,这里定义 $$ 对应的 type 为 NodeExp * 因此可以接收 new NodeExp 返回;最后在每次识别结束时,调用 draw($1); 实际是对已经建立完成的抽象语法树进行语法检查和计算输出等其他操作。
我们可以看到 bison 虽然仅仅包含了少量 C++ 代码,但是实际上组织了整个调用链路,它实际上是整个项目的骨架。而再看 calculator,它里面包含 bison 需要的所有调用的具体实现。这些实现可以非常复杂,而编写 bison 时都无需关心,同样整个抽象语法树的数据结构都对于 bison 是隐藏的。
graphviz 的角色
这个实验的主要目的并不是计算结果这么简单,我们希望将表达式绘制成抽象语法树的形式。通过这种方式方便展示项目的工作,同时也方便检查其中的计算顺序等是否存在问题。
graphviz 实际是一个将代码转换成图片的工具,它拥有一套自己的绘制代码,而作为绘图程序,只需要向文件中输出代码,最后编译成图片即可。关于 graphviz 这套工具的使用,简单阅读程序输出的代码就能读懂,相关拓展询问 GPT 效率更高。
calculator 会在调用 draw 时将绘图代码向重定向文件输出,其中绘制表达式的树形结构、每一步的运算操作和计算结果等。
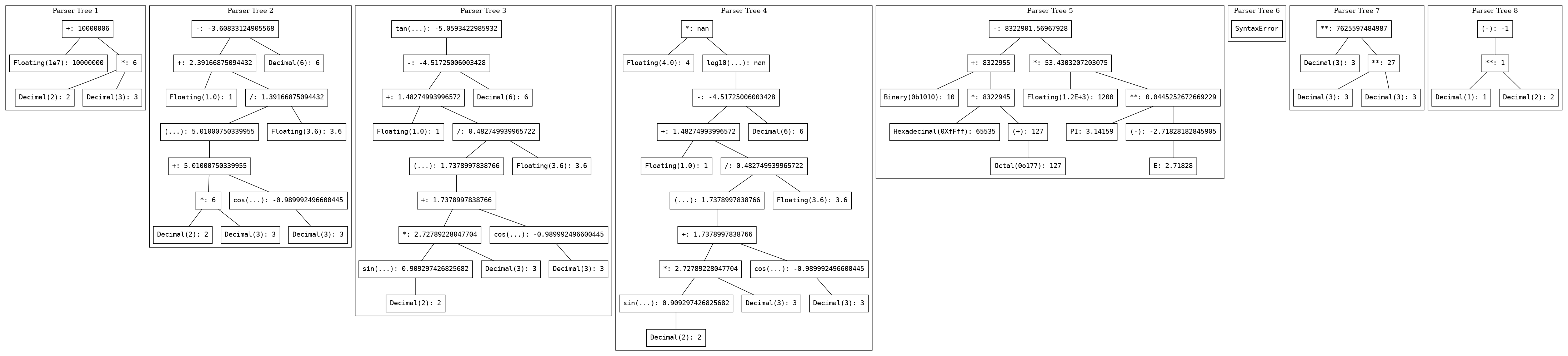
具体代码逻辑
在这里我不想过多解释具体的代码逻辑。它们包括:flex 中正则表达式的书写,bison 中上下文无关文法的书写,calculator 构建抽象语法树和进行语法分析、计算、检查。这是一项繁琐的工作,尤其是最后一项,但是它们组织良好,通过阅读代码和上面的解释相信你可以理解。
