CMU15445 Note
CMU15445 2023fall 个人笔记 | 官方链接 | Start @ 2024-01-14
根据 CMU 官方代码不公开要求,个人笔记部分不会包含任何任务清单相关代码实现,主要总结和记录遇到的问题和解决过程。
Project0 C++ Primer
Task1 Copy-on-Write Trie
Start @ 01-14 | Passed @ 01-16 | 22 hour
如何注册 Gradescope:
在 FAQ 中有写,CMU 为外部学生提供了注册码:
1 | KK5DVJ Carnegie Mellon University (2023 Fall) |
顺便提醒,在代码提交前,make submit-px 后,请运行一个脚本 gradescope_sign.py。它是一个承诺书,不填写承诺书 Gradescope 将拒绝你。
遇到的问题:
这部分进行的可以说非常艰辛,其中主要体现在编译并运行上,而在 Trie 的代码实现上的却不是很多。主要是对于 shared_ptr 与 RTTI 缺乏实践以及缺乏项目编写经验吧。
刚看到这个项目是一脸懵逼的, 甚至不知道项目让我干嘛。然后把任务书来来回回读了好多遍,git 下来了项目找了半天才研究明白到底怎么定位我要写的代码、如何运行代码等等。
阅读一篇 GoogleTest Primer:https://google.github.io/googletest/primer.html。
查阅资料才知道原来注册 Gradescope 可以在 FAQ 解决。
阅读一篇 CMake Tools Quick Start in VSC:https://code.visualstudio.com/docs/cpp/CMake-linux 。
查阅一些网络的其他资料。
先是阅读了一遍 trie.h 文件,里面的 Clone 一直没想明白为什么用 unique_ptr?为什么就实现了拷贝?
后来是代码敲着敲着意识到的,它用的是 make_unique 是拷贝而非引用,而 unique_ptr 是为了保证 Clone 到的元素被使用前是独占的。归根到底是对于 unique_ptr 的不熟悉。
const 类的成员也会加上 const,使得成员无法进行修改,这个 const 容易被忽视。
因为代码中类型名很长,想到了使用 decltype。decltype 直接获取原始类型(可以认为它是个宏),这就能去掉 const;考虑到要修改的代码很多,我写了个宏 #define OriginalConst(var) const_cast<decltype(var)&>(var)。
注意到这个项目使用了大量的移动语义。何时使用 std::move() 是个问题。
需要的场景:
-
具有移动语义,使用后弃用。
-
没有拷贝方法,如
unqiue_ptr。移动语义可以使用匹配拷贝语义,拷贝语义不可匹配移动语义。
默认移动语义场景:
- 临时构造对象,即作为右值被构造的对象。
- 对象返回值时,
return后面的对象。
还值得注意的是,如果在上述两种默认移动语义场景下使用 std::move,cmake 直接报红。
make_shared 的报错问题(构造参数列表错误),它的报错在 new_allocator 标准库中,VSC 识别不到,报错信息也非常奇怪。
-
方案 1. 对
make_shared的奇怪报错产生敏感。 -
方案 2. 使用临时
new创建对象,来替代:1
2sp = std::make_shared<T>(args...) // 使用 make_shared 创建对象,更简短
sp = std::shared_ptr<T>(new T(args...)) // 使用 shared_ptr 创建对象,比较长,可以定义一个宏。
记得最近读 C++ Primer 11,里面提到了智能指针的报错非常奇怪… 当时没什么感受。同时也感受到 VSC 的错误定位能力也有待提高。
RTTI 误判问题,其实 dynamic_cast 没有问题,但需要很小心。
其实到这里我才算理解了头文件中的 Clone() 的意思,其实还是对多态不熟。在代码中的 Clone() 是虚函数,使用它 Clone() 不会改变它的 Runtime Type。而头文件同样提供了构造方法,使用构造方法可能会改变它的 Runtime Type。例如下面的代码:
1 | auto nw = std::shared_ptr<const TrieNode>(ptr->Clone()); // 不改变 Runtime Type 的节点拷贝 |
make_shared 与 shared_ptr 的不同就在于前者实际调用构造函数,它们在 RTTI 中的表现需要用户格外小心,因为它不会在编译时产生提示。
Task2 Concurrent Key-Value Store
Start @ 01-16 | Passed @ 01-16 | 2 hour
涉及知识:
这部分主要为多线程开发入门,它其实对多线程的要求并不高,在完成 Task1 之后这部分很快的完成了。
C++ 的线程锁
在这个项目中,头文件中要求使用 root_lock_ 和 write_lock_ 来保障线程安全,在需要的功能块加锁即可。
其实这部分对多线程的要求并不高,我反倒好奇它的测试程序是怎么写的。我觉得这可以作为学习 C++ 并发的启发点。
简单查阅资料了解到 lock_guard,然后使用了 lock_gurad 替换部分同步原语。
std::optional
这个其实我在 Task1 中用到了,但它在 Task2 中被要求使用。std::optional<T> 通常作为返回值,它可以存储值,另外还可以设置为不存在值。这是此前了解到的,在那之前我通常用 std::pair<bool, T>来实现这个返回值。
更多理解:
Trie 的总体结构理解
从这里我开始理解了我被要求在 Trie 类中实现对象的返回值和权限定义都是合理的。我刚开始还在作将 Trie 中的代码粘贴到 TrieStore 中,刚开始觉得挺愚蠢的,才发现他应该希望我在 TrieStore 中调用 Trie 的接口,这使代码思路清晰很多。在项目要求中没有说明结构或许是希望我自己理解?
更高并发思考
要实现更好的性能,可以实现更细粒化的锁,也就是确保多线程可以发挥更大作用。在这个项目中,所有写操作 Put / Remove 都是完全持有锁的,是否有办法局部持有?这个问题我没有想出一个可行的办法,但按照项目结构,CMU 期待的结果应该就是完全持有的。
上面是我对并发的理解,但这个项目为我提供了进一步的理解。Copy-on-Write 保证了读和写操作是互容的,这同样提供了更好的效率,而且直观的提供了更好的安全保障。
Task3 Debugging
就是让你调试,然后在调试中回答几个问题。很快就能完成,尽管我不是很喜欢这种作答方式。
Task4 SQL String Functions
Start @ 01-16 | Passed @ 01-16 | 2 hour
概要与总结:
个人感觉这部分主要考察多态编程的阅读能力,代码实现方面没有太大难度。
这部分主要带我领略了高度抽象的代码结构,阅读这些代码目前对我来说很吃力,当然也感受到了多态编程的灵活性。其中最另外感慨的是,它使用 AbstractExpression 来解决表达式计算问题。事实上关于其总的结构基本了解,但很多细节目前还没有理解。在解析 Expression 表达式方面我觉得其方法有很大的借鉴意义。

Project1 Buffer Pool Manager
Task1 LRU-K Replacement Policy
Start @ 01-17 | PretestPassed 01-17 | Passed @ 01-18 | 9 hour
第一次思路 (7 hour)
先强调一下,这个思路后面放弃了。
第一个思路是,使用两个链表来解决这个问题,因为之前有接触过 LRU 和 LRU-K。整个时长大概是 9 个小时,但是其中有大约 7 个小时在思考和 Coding 这个思路。我希望将不可驱逐节点当作可驱逐节点的子链存储(不用理解,总之是个错误思路),然后觉得可以 的维护和解决这个问题。最后从考虑解决方案到定好结构到 Coding,用了将近 7 个小时,调试起来才发现存在很大问题。要在原问题上改这个问题要么劣化成 ,要么很复杂,最后重构了第二次思路。
最后我很疑惑网上大篇的解决方案为什么都是链表?然后仔细读完都是 的。
第二次思路 (2 hour)
直接用上平衡树即可解决问题,当然想要更好效率可以用堆,当然 priority_queue 提供的接口是不够的,你可能需要自己实现一个支持删除迭代器的版本。这样做的时间复杂度是稳定的 ,如思路一没有想到 的解决方案。(假设 是常数)
那最后我还是使用手写堆重新解决了一下这个问题。
学到的新东西
首先当然是 LRU-K 的实现原理,当然这在此前就有了解。这里我不想作详细介绍,毕竟讲清楚 LRU-K 或者再介绍点其他缓存策略够写一篇文章。
然后是一些补充 C++ 语法:一点边边角角的知识点,记录一下。
1 | // 枚举类型, 使用示例 |
1 | // 合并类型 (Union), 使用示例 |
1 | // 选参列表初始化 |
线程安全问题 (0.5 hour)
这部分直到 submit failed 后才做,描述一下我的心路历程:
我在本地测试的时候没有做线程安全,因为我一直在考虑使用细粒度的锁来提高并发性能,觉得这不是一个简单的任务。
然后发现本地测试没有作线程测试。(我一直好奇线程安全测试是怎么做的,但很可惜 CMU 提供的 GTest 中没找到。)
一直鸽到了 Task3,发现 LRU-K Replacer 是 Buffer Pool Manager (BPM) 独占的,事实上我只要保证 BPM 安全即可。这应该就是正确的,但评测为 LRU-K Replacer 做了专门的并发测试点,于是 failed 了。
然后是考虑如何做线程安全?水群看到群友说一般就是无脑为每个调用持有 unique_lock,必要时再优化;Task3 中 CMU 还专门提到,BPM 只要求使用最简单的线程安全保障即可。
Task2 Disk Scheduler
Start @ 01-17 | Passed @ 01-18 | 2 hour
一个很简单的实验,主要简单了解多线程和 future。其实还是以阅读外围源码为主。
future 与 promise
用于线程间交流对象,future 是一个接收器 promise 是一个发送器,future 一直等待,直到 promise 返回,注意 future 和 promise 应当使用一次后弃用。
1 | // 注意事项: |
另外,future 和 promise 还有一个特化的模板 promise<> 与 future<>,它不能存储值(或存储 void)。
condition_variable 条件锁
这部分主要体现在 channel.h 中,可以阅读 bustub 用 condition_variable 和 mutex 实现的线程安全队列。这里贴一下源码,关于 condition_variable 用法介绍我注释在了代码里。
1 | template <class T> |
condition_variable 通常用于生产消费模型,它相对于只使用 mutex 会在 wait 时阻塞而避免高占用。
Task3 Buffer Pool Manager
Start @ 01-18 | PrePassed @ 01-18 | Passed @ 01-19 | 6 hour
这部分可以说花了大量的时间 Debug,可以说 Buffer Pool Manager (BPM) 实际只是对 LRU-K Replacer 和 Disk Secheduler 的调度,但我在其中却遇到了很多问题。
需求不明确问题
CMU 在 BPM 的细节方面并没有讲的很清楚,其实这一点不仅实在这次 Lab 中,在之前也有所体现,你需要通过自己的理解来判断其合理的结构。
例如在这次 BPM 中,它没有明确 frame id 和 page id 的定义,让我刚开始以错误的存储结构写了很久,而且在写的过程中一直觉得很奇怪。最后在阅读了本地测试代码后开始意识到:页在整个 BPM 中以 frame id 形式存在,而在 Disk Manger 和 Disk Secheduler 中以 page id 形式存在。好在这个问题可以在原实现基础上修改,大概一小时多就可以完成。
第二点头文件描述中提到需要维护 page 的 metadata,但没有明确这些量需要如何变更等等,这些都是在 submit failed 之后重新阅读和做出修改后完成的。
第三点 FetchPage 之后该不该写脏数据、该不该 RecordAccess、该不该计数 Pin,这些都取决于该函数的职能,而 CMU 并没介绍外部用户会或应该如何使用 FetchPage。
需求遗漏或错误
在这个项目中花了大量的时间 Debug 还有一个原因就是我经常遗漏需求或者错误的实现了头文件中给定的要求,其主要体现在对于异常的处理上。
- LRU-K Replacer 中提到,试图强制驱逐不可驱逐页时,应该抛出异常,而我允许用户强制驱逐不可驱逐页。
- BPM 中提到,试图强制驱逐
Pinned页时,应该返回false,而我仍会试图抛出异常。 - BPM 中提到,试图驱逐不再 BPM 中页时,应该返回
false,而我返回true。
归根到底一是阅读英语导致容易遗忘一些细节,二是代码函数抽离的不够多,导致我无法集中于返回是否符合要求。
Leaderboard Task
Start @ 01-19 | LastTry @ 01-20 | 13 hour

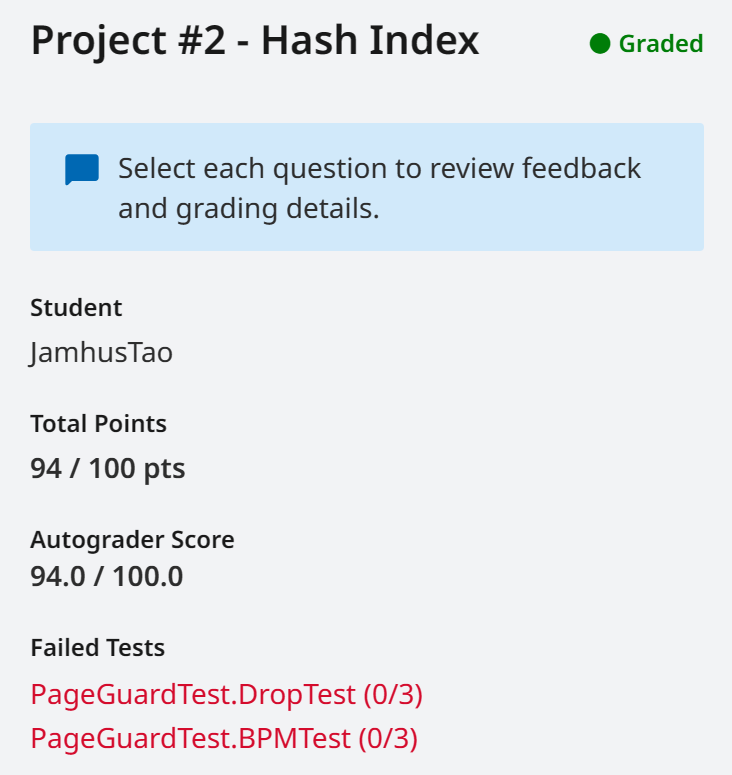
Project2 Extendible Hash Index
Task1 Read/Write Page Guards
Start @ 01-20 | PretestPassed @ 01-20 | Failed | 16 hour
要求完成 Page Guards,它类似于 shared_ptr 的职能,用于自动管理页。其实之前我在写 BPM 的时候就感觉很奇怪,我阅读了测试程序,发现每个页都要自己 Unpin,果然在这一章就让我们实现了 Page Guards。之前也手写过 shared_ptr,相比来说这也算简单了。
但是,这部分 0.5 小时过了本地测试,评测怎么也过不去。通过各种打 LOG 交给评测打印,确实发现了一处问题:移动语义未析构 this,但剩下的花了十多个小时也没 Debug 出问题,最后选择了放弃。感觉这部分 CMU 在很多方面都没有说清楚,有时候我甚至需要观察本地 test 来猜测每个接口需要进行的操作,比如这一部分不但接口没讲清楚,而且不容易通过数据展现。
尚未通过的点:
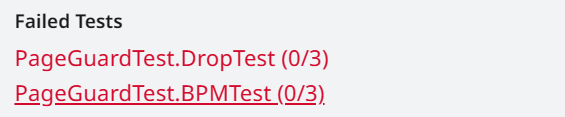
当然,这一部分的痛苦调试虽然未果,但也有收获,我将会在 Task2 中讲到一些调试过程。
Task2 Extendible Hashing Pages
CMU 15445 2023fall 的可拓展 Hash 基于了三级页,在此前都是基于两级的。它们是 Header Page / Directory Page / Bucket Page。Pages 实现与总体逻辑的分离,可以让我在实现总体逻辑时更加专注,但也存在了界限不明确的问题,它与总体逻辑实现(即 Task3)相关性很强,就不单独总结了。
Task3 Extendible Hashing Implementation
Start @ 01-23 | Passed @ 01-24 | 17 hour
使用可拓展哈希表存储键值对的主体实现。
Grow 与 Shrink 问题 (6 hour)
Hash Table 的 Directory Page 层会对 Bucket Page 进行合并或者分割。其实简单的对 Hash Table 的增删查很简单,但是这个 Grow 和 Shrink 的过程就很棘手。
首先谈谈为什么要 Grow 和 Shrink?我们的 Hash Table 分为三层,每层的容量都是 K 级别的,因此我们的 Hash Table 可以存储亿级别的数据。但是,我的理解时当数据集很小时,这些数据会在 Hash Table 中非常松散,当访问数据时,我们必须频繁换页。而对于适合的数据集大小我们选择合适的尺寸自动 Grow 和 Shrink 可以很好的解决这个问题。
然后谈谈 Grow 和 Shrink 的策略,CMU 要求只有当 Bucket Page 满时尝试 Grow,当空时尝试 Shrink,这似乎不是很好的策略,但应该是最好写的,我们必须根据这个策略完成,否则无法通过远程评测。
最后讲讲这一部分我遇到的问题。Grow 和 Shrink 的情况还算复杂,在任务书中将其在 Directory Page 中分为 Grow 和 Shrink,在 Bucket Page 中分为 Split 与 Merge,值得注意的是为保证灵活性,每个 Bucket 的深度还是不一致的。任务书明确要求要支持递归的 Shrink,评测只为其提供了 1 的分值,但却是花了我很长的 Debug 时间,在下一部分我就会讲我的 Debug 过程。

GoogleTest 和打 LOG 调试
Debug 过程是我认为在整个 Project2 中最大的收获,在前两个 Project 中没有在调试方面花费太多的时间,而在 Project2 中至少 70% 的时间被用于 Debug,当然其中很大一部分时间消耗在了没产出的 Task1 上。
总结三种调试方法
断点
断点是单线程编程中最直观高效的调试方式,在此前两个 Project 中也主要以断点的方式调试,使用的 CMake 插件。但它不适合在大型项目中使用,一般对逻辑容易出错的单元进行测试时调试;其优点是它是运行时的,测试人员也无需花太多时间计划调试方案。这不是我主要想介绍的方式。
LOG (日志) 调试
通过输出到文件或终端大量文本的方式调试,它主要有三个优点:
- 无需中断进程,一次获取大量过程信息。一方面大型项目中编译非常费时,一次性获取有时也可以一次发现多个问题;另一方面运行中的后台服务,无需中断它就可以获取其调试信息,这个问题可能非常罕见但它可以一直保存在日志中。
- 快速浏览调试信息。对于复杂数据结构使用断点效率低下,原因是浏览其数据非常不方便。使用日志调试可以通过自定义的方式,选择最直观的数据表达形式。
- 多线程调试中,使用断点会改变线程执行的顺序,这个问题基本无法通过运行时调试解决。
当然日志调试也有很多缺点:
- 日志调试需要大量前期准备。在完成主体逻辑后还要花费大量时间插入日志代码,它还需要测试人员是有计划的。
- 针对快速浏览调试信息,它的代价也是巨大的。虽然使用一些已有的日志方法,可以很快直观打印这些信息,但每个项目的数据结构都是千奇百态的,它仍然需要一些时间为每个项目书写专门的日志方法。
在 bustub 这个项目里,其实很早就提醒我们它提供了 bustub::LOG_DEBUG 等系列方法进行调试。在 Task1 和 Task3 中,我也是在代码段中插入了大量的 LOG_DEBUG,我做这件事情其实是试图窥探远程评测的内容,以及对比我打印的过程信息,比如下面这个例子:

我认为这是一个很好的过程,因为我只能通过日志的方式与远程评测交互,这和从后台服务获取信息很相似。
另外,关于定义直观数据表示,CMU 很友好的为我们提供了 PrintHT 方法,也就是上面看到的这张表,仔细阅读头文件会发现这个方法是实现好的,这也为我们节约了很多时间。
GoogleTest 框架
从这个项目的从始至终,我们都在使用 GoogleTest 进行测试,但是不同的是这次我自己写了一个 GoogleTest,它是一个非常简单易用的框架。这里主要总结我使用 GoogleTest 的过程。
首先我们已经通过打 LOG 的方法从远程评测分析出了时我们程序出现问题的情形,然后就计划将这种情形在本地复现,然后使用断点的方式效率更高。这里我写了一个 my_*_test.cpp 文件,然后把它加入到 CMake 列表中,重新 build 一次就会加入到我们的 make 目标中。当然,阅读了项目中的 CMake 文件,发现它其中的 test 目标是自动搜索的,它会匹配所有 *test.cpp 目标,所以其实直接重新 build 就可以了。然后引入一个 gtest 头文件,在原来的 test 中抄一下启动代码,构造一下需要的情形即可。
PageGuard 再封装规范化 (2 hour)
Task1 让我们实现的 PageGuard 是真的不好用(可能因为我 Task1 没过才这么骂它),我用 this->bpm_->FetchPageBasic 后还要将结果 As 为我需要的类型,而这个操作又是高频操作,我决定将它再封装。这个新的封装会同时持有一个 BasicPageGuard 和转换好的目标 Page 对象。
1 | // HTablePageGuard.h |
1 | // HTablePageGuard.cpp |
哎,这样子用起来舒服多了。
减少 BufferPoolManager 占用 (0.5 hour)
这是一个很坑的点,任务书中没有强调会对 BufferPoolManager 作严格的限制,但实际中有一处严格限制了 BPM 只能同时持有 3 页,因为我们的 Hash Table 分为三级,而在 Shrink 时还需要查看其他页面,如果不注意释放就会超过。还好在我的做法中,向 BPM 申请页面失败时会抛出异常,比较好定位到问题,最后还是通过打 LOG 的方法证实了问题。其实我们注意释放的话,可以做到只同时持有 2 页。
Task4 Concurrency Control
Start @ 01-25 | Passed @ 01-25 | 2 hour
实现前面 Hash Table 的并发安全。
shared_mutex 为 lock 时 unlock 疑似 Undefined Behavior
我在未检查 Page 对象是否上锁的情况下直接读写锁都释放一遍。编译时没有出现任何警告,运行时也没有任何警告,但是出现了死锁。
查阅一些资料后发现,在空释放锁是未定义行为,而重复上锁也是未定义的。
前面我们有讲使用 unique_lock 或 lock_guard 实现 RAII 的互斥锁自动管理,而 shared_lock 则用于管理共享锁。
1 | std::shared_lock<std::shared_mutex> lk(rwlatch); // 等价于: rwlatch.lock_shared(); |
锁升级获取高效并发
注意到在这个并发场景下,Header Page 和 Directory Page 两级索引页很少被修改,因此可以使用锁升级的方式减少资源互斥。这里我们通过改写 HTablePageGuard,当 PageGuard 的 operator-> 方法以 const 调用时持有读锁,而当非 const 调用时将锁升级为写锁。
1 | template <typename PageType> |
这样我们只需使用 const_cast 细致的为每次调用限制 const 即可。