MapReduce 论文研读 - MIT6.824
前言
这个部分来自课程 MIT6.824,这门课每节课都会精读一篇分布式系统领域的经典论文,并由此传授分布式系统设计与实现的重要原则和关键技术。
个人认为阅读论文比课程本身更加重要,课程围绕论文展开,可以快速获取论文的核心观点,课程的一切细节以及未提及的内容在论文中具有最详细的解释。另外教授会从当今立场(2022)评价论文的意义和缺陷,同时可能补全论文中缺失的信息解释,教授对学生提问的一些回答具有很好的启发意义,这些内容不被包含在论文中。
本文综合课程内容和论文核心观点,并参考一些其他资料整理,希望对你学习课程有所帮助。
课程官方:https://pdos.csail.mit.edu/6.824/
博主整理:https://mit-public-courses-cn-translatio.gitbook.io/mit6-824
B 站录屏:https://www.bilibili.com/video/BV1qk4y197bB
请阅读论文 MapReduce: https://pdos.csail.mit.edu/6.824/papers/mapreduce.pdf
什么是 MapReduce?
MapReduce 是一个运行在分布式系统上的计算模型,它允许用户在不了解分布式系统的情况下,轻松使用该模型并发挥出分布式系统的性能。MapReduce 将分布式系统的操作做了高度的抽象,它相较于前人提出的计算模型更加简单易用。
MapReduce 由 Google 设计,在 2004 年提出。那时 Google 急需一种高效的计算模型,例如为数 TB 的网页数据创建索引,进行排序。因此当时 Google 需要一种可以利用分布式资源的计算模型,这样 Google 的工程师也不再需要花费大量的时间看报纸等待运行结果。Google 具有大量优秀的工程师可以熟练的使用分布式系统,并完成这样的大型计算。然而 Google 想雇佣各方面有特长的人,而不是花费大量的时间用于运行分布式系统,它希望一种简单易用且稳定的计算模型,这样具有各方面特长的工程师可以轻易的使用分布式资源。
因此 MapReduce 反复强调其设计初衷是简单易用和抽象,用户只需实现 Map 和 Reduce 函数即可将它运行在分布式系统上。
基本工作方式
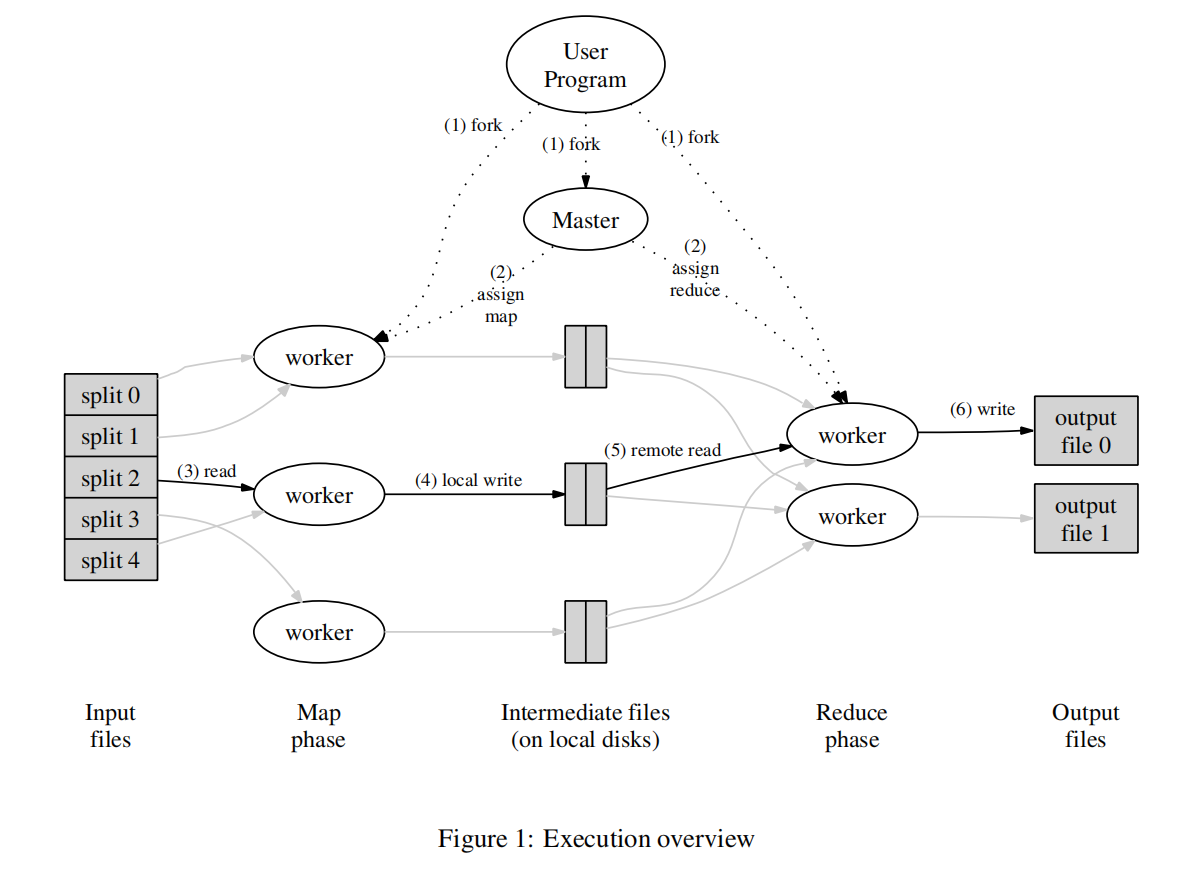
MapReduce 由 master、map worker、reduce worker 三个角色组成,数据在其中经历 Input、Intermediate (Shuffle)、Output 三个阶段,所有数据以键值对的形式存在。
- Input:首先 user 将启动 master,然后 master 指定离输入文件网络距离最近的一些机器为 map worker。map worker 对指定的切片进行用户定义的 Map 操作并将结果保存在本地,然后向 master 发送中间结果位置信息。
- Shuffle:master 会将剩余的 worker 指定为 reduce worker。master 将 map worker 发送的中间结果位置信息转发所有 reduce worker,reduce worker 从这些数据中抽取满足分布函数的数据到本机。分布函数是指,例如共有 R 个 reduce worker,则 的数据应该被抽取到 号 reduce worker。
- Output:reduce worker 将所有数据抽取到本地后,先对这些数据进行排序聚合,再进行用户定义的 Reduce 操作,最后写入全局的输出文件中。
Map 函数和 Reduce 函数
上面我们讲到了 MapReduce 具有两个用户自定义函数:Map 函数和 Reduce 函数,但并未介绍它们的功能,这个部分我们将从两个示例介绍如何使用 MapReduce,完成 Map 函数和 Reduce 函数就完成了 MapReduce 的编写。
Map 函数是从 的映射,而 Reduce 函数是从 的映射。在调用 Reduce 函数之前, 已经进行了排序聚合,即将具有相同键的值放在一个列表中并按键排序。因此,Reduce 函数调用时保证 是有序传入的。
一个示例是从大量字符串集中筛选符合样式的字符串。Map 函数对符合样式的原样返回,不符合的不返回即可,而 Reduce 函数直接返回 即可。因为符合样式的字符串通常不会太多,我们设置 即可将它们输出到同一文件。
另一个示例是计数大量样本中的词频。这里 Map 函数返回 ,而 Reduce 函数返回 即可。不过对于这个问题,我们发现网络开销远大于处理开销,MapReduce 提供了在跨越网络前进行 Reduce 的方法,它称为 Combiner (论文 4.3)。
通过大量实践,我们发现多数数据处理问题都可以分离成 Map 和 Reduce 两个过程,这也使得高度抽象的 MapReduce 模型依然实用。如果对于 MapReduce 的过程还有疑问,论文的附录包含了词频统计的示例代码,它对理解如何定义 MapReduce 非常有帮助。
容错和优化
master 会将整个 MapReduce 任务 (Job) 切分为多个 map 任务 (Task) 和 reduce 任务 (Task),于是每个任务具有一个状态:空闲 (idle)、处理中 (in-progress)、完成 (completed),如果任务处于后面两种状态状态将记录其执行者 (worker)。
master 会周期性的 ping worker。如果 worker 未在周期内响应,master 会认为该 worker 故障。这时 master 会重新执行属于该 worker 的所有 in-progress 任务,如果是 map worker 还将重执行所有属于其的 completed 任务,因为 map worker 的处理结果存储在本地,这些资源都将离线。由于 master 进行了重执行,可能存在网络延迟被误判为故障而导致多次提交。对于 map 任务,master 会忽略其重复提交请求;而 reduce 任务的提交动作是将本地文件重命名到全局,这个行为是原子的,具体行为由底层分布式系统 (GFS) 定义。
在优化方面,前面提到 master 会将 map worker 分配在与输入数据网络距离最近的位置。不过 reduce worker 无法这么做,因为它会从所有 map worker 抽取数据。另一方面,少数机器可能由于运行缓慢而严重拖慢整个任务 (Job) 的结束。为解决这个问题,当整个任务 (Job) 即将结束时,master 会重执行所有进行中任务 (Task) 从而绕过运行缓慢的任务 (Task)。
MapReduce 的缺陷
MapReduce 存在它的不足之处,MapReduce 为用户提供抽象的同时,做出了限定性。例如,你只能通过实现 Map 和 Reduce 函数实现分布式。
Robert 教授提到:无论如何 MapReduce 在 Shuffle 和 Output 阶段不可避免的存在网络传输。在 2004 年,网络带宽成为制约 MapReduce 的主要瓶颈;而 2020 年 Root 交换机不再是一台,通过多根负载均衡(Spine-Leaf 架构),现在的网络吞吐量远超从前。我认为 Google 几年前就不再使用 MapReduce,不过在那之前现代的 MapReduce 已经不再使用 GFS,因为网络带宽不再在乎我们从何处读取。
