Google File System 论文研读 - MIT6.824
前言
这个部分来自课程 MIT6.824,这门课每节课都会精读一篇分布式系统领域的经典论文,并由此传授分布式系统设计与实现的重要原则和关键技术。
个人认为阅读论文比课程本身更加重要,课程围绕论文展开,可以快速获取论文的核心观点,课程的一切细节以及未提及的内容在论文中具有最详细的解释。另外教授会从当今立场(2022)评价论文的意义和缺陷,同时可能补全论文中缺失的信息解释,教授对学生提问的一些回答具有很好的启发意义,这些内容不被包含在论文中。
本文综合课程内容和论文核心观点,并参考一些其他资料整理,希望对你学习课程有所帮助。
课程官方:https://pdos.csail.mit.edu/6.824/
博主整理:https://mit-public-courses-cn-translatio.gitbook.io/mit6-824
B 站录屏:https://www.bilibili.com/video/BV1qk4y197bB
请阅读论文 GFS: https://pdos.csail.mit.edu/6.824/papers/gfs.pdf
什么是 GFS?
在 GFS 出现之前,分布式系统实际已经进行了数十年的学术研究,但事实上在工业上它仍然很少被认可。在 2003 年,实际上互联网规模已经相当巨大,像 Google 这样的大数据公司开始实际使用分布式系统。GFS 几乎作为第一个严格意义上的分布式系统,它做了很多工作解决包括性能和容错性上的问题,在相当长的时间内颇具影响力。
GFS 的设计目标
GFS 的设计目标包括:大容量、快速、全局共享、容错、自动恢复。
GFS 的局限性:
- GFS 的设计仅局限于一个数据中心,它并未将数据分布到世界各地。
- GFS 始终是 Google 内部使用的系统,Google 从未直接向外部售卖 GFS 系统。
GFS 的特征:
- 数据切片,它将大文件切片存储在不同机器上。
- 大型顺序 IO 场景,GFS 被设计用于大型顺序 IO,它不对小规模随机访问进行优化。
- GFS 在当时并没有提供新颖的想法,但它是第一个被用于工业界的系统。
- GFS 并不保证返回正确的数据,这样的弱一致性在当时是反学术的。
GFS 的 master 节点
GFS 集群中,具有三种角色:master、chunkserver、client。其中,master 采用主备模式,一个集群中只有一个 master 在工作。
master 的数据结构
master 仅用于存储元数据,它仅包含这三类数据:文件空间域、文件到 chunk 的映射关系、chunk 所在的位置。每个 chunk 的大小为 64MB,当 client 获取文件时,首先向 master 获取文件包含哪些 chunk 以及它们的位置,然后 client 直接从对应的 chunkserver 获取数据。具体地,master 的数据主要有:
- File(文件空间域和文件到 chunk 的映射关系)
- Chunk ID 列表。
- Chunk ID(chunk 所在的位置)
- 每个 chunk 所在的 chunkserver 列表,表示多个副本位置。
- chunk 对应的最新版本号(Version),版本落后表示已失效。
- 主 chunk(Primary Chunk),所有写控制从主 chunk 开始,它是多个 chunk 副本之一。
- 租约到期(Lease Expiration),主 Chunk 只在租约时间内担任主 chunk,一份租约是 60 秒。
master 的容错性
master 包含的三类元数据中,文件空间域和文件到 chunk 的映射关系使用 NV(非易失性)方式存储,而 chunk 所在的位置及其一些相关信息(chunkserver 列表、主 chunk、租约到期)使用 V(易失性)方式存储。例外地,chunk 的最新版本号应该是 NV 方式存储的,我们后面会讲到为什么。
对于前者的 NV 方式存储,包括以下两个方面:每次操作元数据的 Operation Log 同时在主备 master 存储,一旦宕机重启,从 Operation Log 顺序恢复;当 Operation Log 达到一定数量,生成 checkpoint 快照并清空 Operation Log,这样有利于平衡容错开销。
对于后者的 V 方式存储,即无需额外容错开销。master 启动时,从 chunkserver 获取 Chunk ID 和 Version 信息。至于主 chunk 和租约,完全可以遗忘并重新任命。
另一方面 master 具有 standby master 和 shadow master。standby master 可以在宕机时接替工作,而 shadow master 可以提供短期的只读服务和分担部分 master 压力。
GFS 读文件
当 client 需要读取文件时,它会首先询问 master 主机。client 将告知 master 包括文件名、文件偏移量、读取字节数,master 通过两表查询会告知这段文件所在的 Chuck ID 的所有相关信息。client 得到这些信息后从相应的 chunkserver 请求数据。
需要注意的是:
- client 会缓存 master 返回的这些元数据,这样 client 有时不再需要向 master 询问。这些缓存会在租约过期、文件关闭、缓存池满时清理。
- 当出现数据跨 chunk 时,由 client 将询问切片后询问 master。虽然 client 不知道这些数据在哪个切片中,但它可以计算哪些数据在一个切片中。这样做的好处是,client 可以充分利用缓存的元数据。
- client 将获取 chunk 的所有副本位置,这时 client 会选择最近的 chunkserver 请求数据,由于在 Google 的数据中心,IP 地址是连续的,client 可以轻易的计算其中最近的 chunkserver。
GFS 写文件
具体而言,这个问题是如何追加文件,它与写不同,就像 write mode 和 append mode 的区别。
GFS 的写操作相较于读操作复杂的对,因为它需要保证多个副本之间是一致的。当 client 需要写入文件时,它会首先询问 master 主机。client 同样将告知 master 包括文件名、文件偏移量、读取字节数,master 通过两表查询会告知这段文件所在的 Chunk ID 的所有相关信息。
client 获取的这些信息包括 chunk 所在的 chunkserver 和其中的主 chunk 及租约时间。我们将持有主 chunk 的 chunksever 称为 primary,将持有其他副本的 chunksever 称为 secondary。client 首先通知 primary 准备接收数据,primary 将通知所有 secondary 准备接收数据。然后 client 会将数据发送到 primary 和 secondary,它们(primary 和 secondary)会首先将数据存储在临时文件中,然后追加到 chunk 中。如果这一切正常,secondary 将发送成功响应到 primary,primary 确认所有响应成功后发送成功响应到 client。
如果 client 收到异常响应或者未收到响应,client 将重试整个流程。最后 client 还会缓存 master 返回的这些元数据,这样 client 有时不再需要向 master 询问。同样地,缓存会在租约过期时清理。
需要注意的是,client 的数据传输具有不同的传输路径,我们称之为数据流,而称之前的传输方式为控制流。与控制流不同,数据流更专注传输效率,数据流会从 client 发送到网络距离最短的 chunkserver A,然后 A 将它转发到剩余最近的 chunkserver B,依此类推。我们称之为 pipeline 模式,它的优势在于均衡交换机负担,同时更好利用全双工模式。
版本和租约 (Version & Lease)
我们在之前多次提到了版本(Version)和租约(Lease)的概念,但并未介绍它是如何工作的。版本和租约定义了 primary 的任期时间和任期版本,每次分发租约时将更新版本。版本和租约在 GFS 的容错机制中具有相当重要的地位。
由于一些 chunkserver 可能暂时处于离线状态,当它恢复并重新加入系统时,其上的 chunk 版本可能是陈旧的。如果 chunkserver 使用了陈旧的 chunk 版本,它会被 master 忽视。master 会将不足数量的 chunk 拷贝到其他 chunkserver,而这些陈旧的 chunk 版本会在连接上 master 后定期清理。
当一个写操作到达 master 时,它会查询 chunk 的 primary 及其租约时间。如果 primary 不存在或者租约过期,master 会重新指定一个 primary,并更新当前 chunk 的版本。然后正如我们先前描述的那样,client 将完成后面的流程。
值得注意的是,租约只会在过期时分发。例如 primary 失去连接,master 不会重新分发租约,而是等待租约过期。因为这里可能存在网络分区的问题,这时在这个网络中 primary 可能对 client A 或 master 是不可见的,而对 client B 是可见的。这时如果重新分发租约,那么在这个网络中就存在两个 primary 是局部可见的(因为 client 存在缓存),这种现象称为脑裂,也一定会产生一致性问题。我们通过租约协调这个问题,即使存在网络分区,当一个分区的 primary 被任命时,另一个分区的 primary 将自动过期。
有学生提出,既然每次 client 向 master 提出请求,master 为何不每次指定 primary?首先是并发问题,如果存在两个 client 对同一个 chunk 执行写操作,它们必须由同一个 primary 指定其次序,否则就出现了脑裂。其次 client 是存在缓存的,因此它不一定每次向 master 请求。最后网络在传输过程中可能存在延迟,网络重试可能比他更快到达,这时也会存在冲突。
我们回到写操作。由于 master 只会在租约过期时重新分发,因此如果一些机器不可逆的发生故障,那么它只有在租约过期时才有可能重新恢复。当然一些网络故障通过重试即可解决。另外一个需要注意的点是,虽然我们的写操作返回了异常,但它可能依然存在正常的副本,之后的读操作可能读到正常的数据也有可能是缺失的,这对一个分布式系统而言是可接受的。
GFS 的一致性
GFS 是弱一致性系统,也就是说它可能存在一致性问题。
当 client 追加数据段 A 时,它可能是成功的,这时所有副本都将包含数据段 A。然后追加数据段 B 时,可能某个 secondary 失败了,这时将出现重试。其中我们成功追加了数据段 C,然后数据段 B 的重试成功。当然,也有可能出现 D 追加失败,并且重试失败。于是如图中所示,我们的 chunk 可能存在空缺(padding)和重复(duplicate),更糟糕的是如果不断重试它的重复可能进入下一 chunk。
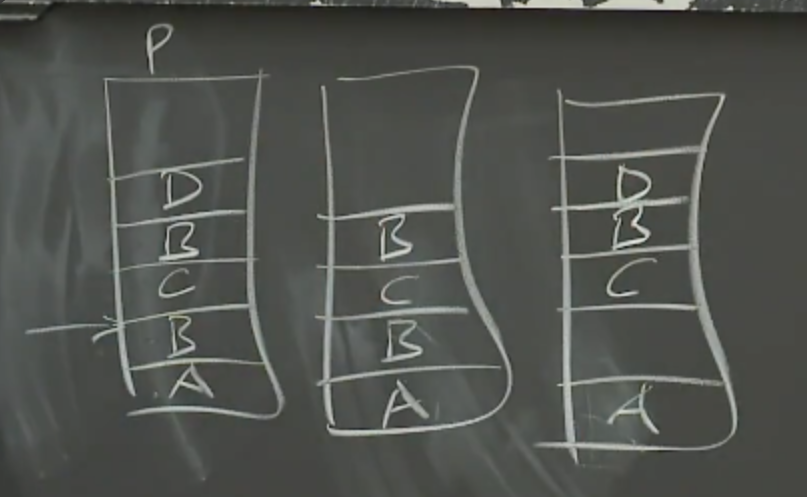
GFS 的应用应该具有容许错误的能力,例如在收到错误响应时,应用应当自动过滤其中缺失的数据。我们提供 checksum 用于检测 chunk 的数据完整性,这可以用于验证是否存在空缺和重复。另外如果你的数据存在幂等性问题,你必须剔除重复数据,这可以利用唯一标识区分,这些方法被包含在我们的库中。
目前没有将 GFS 改进为强一致系统的方案,不过它发布的前 5-10 年在 Google 具有非常出色的表现,许多 Google 的基础架构例如 BigTable 和 MapReduce 都运行在它上面。
副本放置与回收
GFS 考虑副本放置策略出于负载均衡和容错性的考量。副本放置会发生在以下场景:副本创建、失效重放置、重平衡。
出于负载均衡的考量,GFS 会将新副本放置在负载最低的 chunkserver 中;另一方面,出于容错性考量副本必须是跨机架的,因为同一机架下的 chunkserver 可能同时离线。考量的第三个方面是重要性考量,对于副本创建是立即的,GFS 必须立即执行创建。而失效重放置和重平衡作为后台任务进行,他们以较低的速率运行避免抢占立即任务资源。在这里失效根据失效副本数排序,失效副本越多的 chunk 更急切完成拷贝放置以避免损失数据。而重平衡优先级最低,它会在空闲时将副本从一个 chunkserver 移动到另一个,从而完成负载均衡。这些任务均在 master 的控制下完成。
GFS 提供了垃圾回收机制,同样以缓慢的后台任务清理失效副本。失效副本主要包括两种:租约过期的副本、用户删除的副本、损坏的副本,其中租约过期是租约版本低于最新版本的副本,它通常是 chunkserver 在一段时间离线导致的。这些副本会在被 master 检测到时从 metadata 删除,然后 chunkserver 会定期发送心跳,这些数据包含了部分 chunkserver 的本地 chunk,它会在多次心跳中扫描全部本地 chunk。每次 chunkserver 发送心跳,master 将回复哪些 chunk 不在 master 的 metadata 中,然后 chunkserver 将清理这些 chunk 和相关的 metadata。可以发现这样被动的垃圾回收机制更加简单可控。
GFS 的缺陷
GFS 作为单 master 的分布式系统,向业界证明了单 master 系统依然可以很好的工作,但也是单 master 成为了系统很多的缺陷所在。
- master 存储了所有的元数据,随着文件的增加,这些数据可能会占满其资源。
- master 需要支持数千台机器的集群,而 master 的 CPU 每秒只能处理数百个请求。
- master 的主备切换不是自动的,它需要人工干预或外部设施支持,前者可能需要等待几个小时。
- 另外一点就是 GFS 奇怪的语义可能为应用带来一些困扰,尽管这些不一致性发生的概率很低。
- 网络是制约当时 GFS 这类分布式系统的主要瓶颈,这些系统早已不再使用。
